



Although there are many extensions to improve the SEO of a site, they are generally limited to adding additional fields for SEO tags to CMS, but do not take into account the final rendering of the pages which may be different once the HTML code is rendered and sent to the browser. Screaming Frog allows you to index (crawl) a site like a search engine spider by collecting important technical information on the pages visited such as the status of links, images, SEO titles, meta descriptions, page loading speed, http headers, even spelling or any custom character strings.
Its main interest is to quickly provide a complete view of a site or its competitors. On a site with a large number of pages, automation makes it possible to correct problems which might not have appeared during a manual check and therefore to optimize the overall quality of the site and its SEO. This commercial application installs on a Mac, Linux or PC computer and benefits from rapid support in the event of a problem. Unlike other SEO services, the price is affordable and there is a free version limited to 500 URLs to get an idea of the capabilities or usefulness of the software before purchasing.
Configure the application
Before launching the crawl of a site which can take time depending on the number of pages to index, it is necessary to adjust some preliminary settings:
- Activating Dark mode is useful when viewing numerous data tables (in configuration > user interface).
- Put the storage in database mode to avoid running out of RAM issues.
- Set the speed of the spider.
- Connect with APIs of Google Analytics, Google console search, Google Page Speed or other supported SEO software.
- Connect with API of IAs like Gemini or OpenAI.
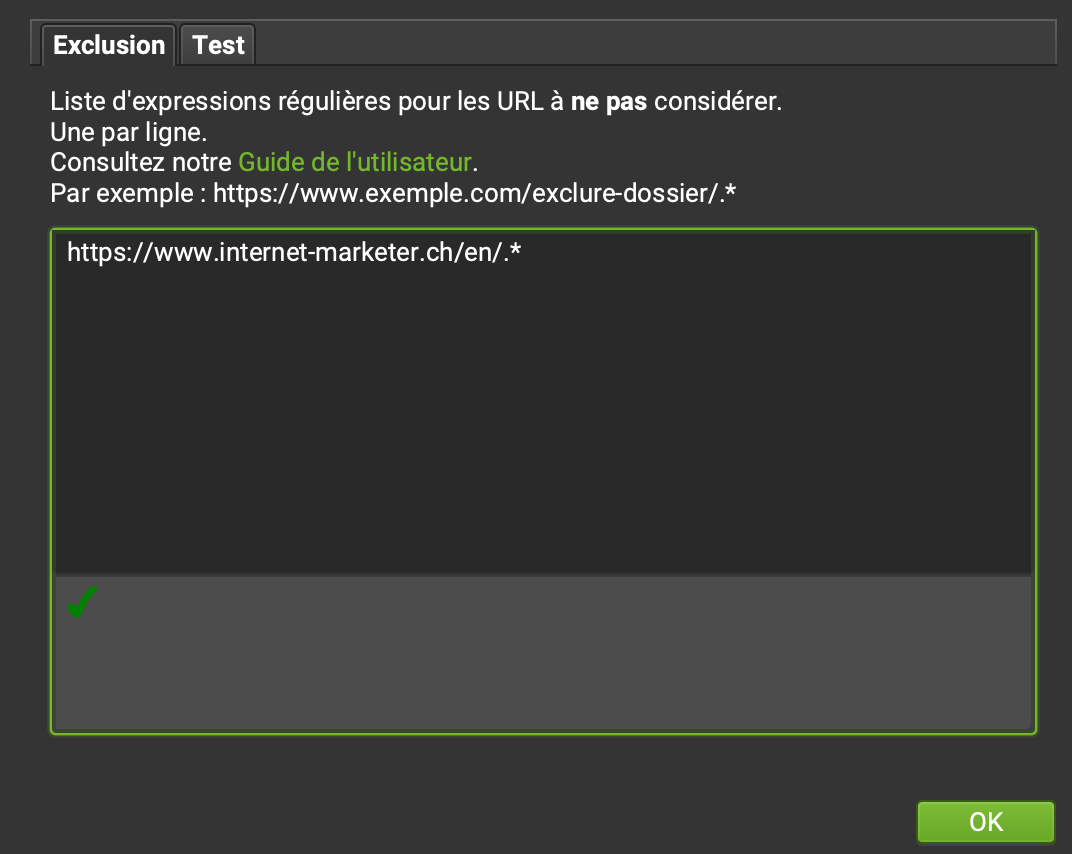
Crawl a page, a part or the full website
- It is possible to indicate the address of your website, a subdomain or the URL of a specific page, which is very practical for checking your work after a modification.
- On large sites, limit the crawl to one language, especially if you check the spelling, or by deleting certain folders such as images.
- Conversely, it is possible to define a list of URLs to crawl by switching to List mode. URLs can be entered manually or as an xml sitemap.
How the interface works
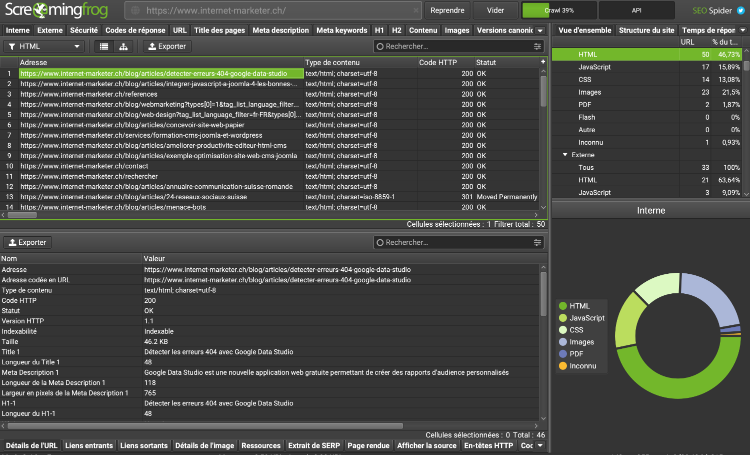
The list of links is gradually displayed in the top left quadrant as soon as the indexation process is launched. It is possible to filter certain types of links with a drop-down menu (example: HTML, images, scripts, css, etc.). Clicking on a link allows you to learn more in the bottom quadrant. The tabs in the two quadrants allow you to cross-reference the data in multiple ways. For example, to check outgoing links, we will click on the External tab at the top and Inbound links at the bottom to define the original page. The right quadrant presents a summary of all the results and it is possible there to click on a data type to display the corresponding links, for example all Javascript files. An interesting feature present in this quadrant is a summary of site issues. Clicking on a problem, for example "Pages Titles Duplicate", will display all the affected pages in the left quadrant.
Additionally, each link crawled by the spider can trigger a context menu to perform many additional operations, for example checking the presence of the link in the Google index or cache, obtaining backlinks using a commercial API, visualize the link in 3D graph, validating the link's W3C compliance, its display speed, copy the link or remove it from the list if it has been corrected.
It's very effective. It is possible to export the results in csv format and many reports are pre-configured.
The rest of the article presents some examples of use of this software.
Check site links
Links are the basis of how the web works and maintaining their integrity over the life of the site is crucial both for search engine optimization, but also to provide a good user experience to your visitors and to save money by reducing the usage of your server resources.
- Internal and external broken links.
- Pages with too few inbound links (inlinks).
- Insecure links (without the https protocol).
- Links to external scripts.
- Non-canonical (non-unique) links.
- Links to the development server.
- Broken fragments, for example in internal links on the same page.
- Redirect status and redirect code. Check that redirects are working correctly or turn redirected links into direct links, which is very useful after migrating a site.
- Links blocked by robots.txt file.
- Links blocked by directives like nofollow or noindex.
- Parameters in the URL or presence of special characters.
Check HTML pages
- Check the presence or absence of titles with the h1 and h2 tags and if there are duplicates.
- Check text size, similarity and duplicate content (with different URLs).
- Check spelling. Be careful to configure the spelling and grammar check beforehand and to limit the scan to one language of the site. Errors are displayed in the Content tab and in the bottom quadrant by selecting Spelling & Grammar.
- Check the site compliance to accessibility rules.
- Check for unused shortcodes.
- Check the integrity of the head and body tags using the new Validation tab.
- Search for snippets of text or HTML you need to update or remove.
- Extract any element from the HTML page using XPath language.
- Detect the differences between a site in production and a site in development.
- Check the HTML page and its assets response time.
Check SEO tags
SEO tags are not visible in the site content, Screaming Frog allows you to make a list that is easy to check at a glance:
- Check SEO titles of HTML pages: text, length and presence of duplicates.
- Check meta description tags: text, length and presence of duplicates.
- Meta keywords tags are no longer used by Google and even abandoned in certain CMS, but it can still be useful to check their presence on certain sites.
- Ask a connected AI to improve SEO tag content.
- Meta robots tags.
- Verify and validate structured data in microdata or json+LD format.
- Visualize the appearance of each link in search engine results (snippet).
Check the integrity of media (images, videos)
It is possible to display the URLs of images that generate an http code 404 or 403 (broken or prohibited images) in the following way:
- click on the Response Codes tab, then create the following search filter:
Address Contains '.png' or Address Contains '.jpg' or Address Contains '.svg' - from the drop-down menu, choose Error 4xx.
- In the bottom quadrant, choose Incoming Links to find the origin of the broken image.
The software also checks the size of all the images, the presence of width, height and alt attributes and the length of the alt attribute. It is possible to export as an Excel file all the image links with the texts of the alt attribute, in order to be able to check them more easily.
Have you ever wondered if an image is still used on your site? A simple search for the file name in the list of internal links will confirm this. This is not only true for images, but also for all CSS, Javascript, PDF, etc. files.
Check other technical data
In Configuration > Spider > Extraction, you can configure the extraction of various technical data in your crawl. Among the most useful for me:
- Cookies.
- Http header.
- Page size.
- Last modified date.
Examine the site structure
It is possible to visualize the network of links on a site in the form of a tree or nodes with a system that weights their respective weights. This makes it easy to see if certain parts of the site are isolated from the main structure and if navigation is inefficient. An analysis function makes it possible to assign a "link score" to each link, much like Google's "Pagerank", and therefore to determine pages with a strong or weak link structure.
Pages indexed in search engines
- The software offers numerous settings to create an XML sitemap of the site for search engines, which is interesting for a site with a static tree structure. The advantage is of course to provide the search engine with a verified and error-free sitemap.
- By connecting SF to the Google search console API, it is possible to check which pages of the site are not indexed by Google et when was the last time Google Bot crawled every page.
Keyword Analysis
A list of keywords can be extracted from a competitor's website or your own using the various information provided by Screaming Frog such as the SEO title, meta description, H1, H2 or other tags through custom extraction.
Security
The Security tab allows you to list missing security http headers like hsts or x-content-type-options. Another very useful function is to be able to determine the remaining links which do not use the secure https protocol.
Performances
It is possible to connect SF to the free Google Page Speed API or to the local Google Lighthouse. It then becomes possible to create a complete report of the core web vitals of all pages on the site and filter them according to suggested improvements, for example all pages where images need to be optimized.
Latest version of Screaming Frog can check the carbon footprint of every page in any website. Do not forget to set in the configuration if the hosting provider has an environmental friendly infrastructure.
Comparison between two crawls
Screaming Frog's Compare mode allows you to determine what has changed between two crawls.
Screaming Frog does not present itself as a miracle solution for getting better ranking in search engine results. Rather, this software offers a range of tools with a large number of parameters to better analyze websites and optimize every technical detail for providing professional quality work. Good technical knowledge is therefore necessary to take advantage of its capabilities and to make all the modifications to your website. You can click on the link below to learn more about its different features:
Source: Screaming Frog Documentation
{kind=link}